AIUI文档中心
AIUI文档导览
1. AIUI平台服务
1.1 AIUI平台介绍
1.2 AIUI应用介绍
1.3 AIUI服务链路介绍
1.4 AIUI平台能力概述
1.5 快速体验
2. AIUI应用配置
2.1 应用发布
2.2 语义精简协议介绍
2.3 基础配置
2.4 语义模型配置
2.5 回复角色配置
2.6 语音识别配置
2.7 结构化语义配置
2.8 星火大模型配置
2.9 语音合成配置
2.10 应用后处理配置
2.11 三方大模型配置
2.12 流畅全双工交互配置
2.13 表情标签配置
2.14 长时记忆配置
2.15 声纹识别配置
3. AIUI SDK开发
3.1 AIUI SDK接入流程
3.2 AIUI SDK基础信息
3.2.1 SDK接口说明
3.2.2 参数配置说明
3.2.3 消息事件说明
3.2.4 SDK状态说明
3.2.5 数据发送方式
3.2.6 回调解析说明
3.2.7 交互结果协议说明
3.3 AIUI SDK基础能力
3.3.1 流式识别
3.3.2 离线识别
3.3.3 语音唤醒
3.3.4 语音合成
3.3.5 用户个性化
3.3.6 自定义参数
3.4 传统语义链路接入
3.4.1 链路配置说明
3.4.2 个性化数据使用
3.5 通用大模型链路接入
3.5.1 链路配置说明
3.5.2 个性化数据使用
3.5.3 超拟人合成
3.5.4 声音复刻
3.6 极速超拟人链路接入
3.6.1 链路配置说明
3.6.2 个性化数据使用
3.6.3 流式合成
3.6.4 声音复刻
3.6.5 RTOS系统SDK接入
3.7 错误码列表
3.8 发音人列表
4. AIUI API开发
4.1 传统语义链路
4.1.1 交互API
4.1.2 用户个性化API
4.1.3 合成能力使用
4.2 通用大模型链路
4.2.1 服务鉴权
4.2.2 交互API
4.2.3 用户个性化API
4.2.4 声音复刻API
4.2.5 合成能力使用
4.3 极速超拟人链路
4.3.1 服务鉴权
4.3.2 交互API
4.3.3 用户个性化API
4.3.4 声音复刻API
4.3.5 合成能力使用
4.3.6 声纹管理API
5. 自定义业务
技能工作室概述
名词解析
技能
意图和语料
实体
动态实体
模糊匹配
填槽对话
技能设计规范
语音技能设计规范
开放技能接入审核规范
开放技能图标图片规范
技能开发
创建技能和意图
意图配置
技能测试
技能发布
技能后处理
技能导入导出
云函数APIv2.1
云函数APIv2.0
智能体开发
智能体对接
问答库开发
语句问答
关键词问答
文档问答
设备人设开发
技能协议
语义协议:重要字段和通用字段
技能后处理协议:标准请求
技能后处理协议:请求校验
技能后处理协议:Request_v2.1协议
技能后处理协议:Response_v2.1协议
技能资源限制
6. 硬件模组
RK3328 降噪板
RK3328降噪板白皮书
RK3328降噪板使用手册
RK3328降噪板规格书
RK3328降噪板协议手册
RK3328 AIUI评估板开发套件
RK3328评估板白皮书
RK3328评估板使用手册
RK3328评估板规格书
RK3328评估板开发手册
RK3588s 极简通用多模态开发套件
RK3588s 极简多模态套件白皮书
RK3588s 极简多模态套件使用手册
RK3588 AIUI多模态开发套件
RK3588一体机多模态产品规格书
RK3588多模态套件使用手册
视频传输协议
识别语义传输协议
音频传输协议
AIUI类型消息事件
ZG803 离线语音识别套件
ZG803 产品白皮书
USB声卡套件
USB声卡产品白皮书
USB声卡使用指南
AC7911B AIUI语音开发套件
AC7911B-产品白皮书
AC7911B-快速体验指南
AIUI评估板接入
集成方式
软件包说明
AIUIServiceKitSDK
串口SDK
评估板参数配置
调试升级
7. 常见问题处理
7.1 AIUI常见问题
7.2 评估板常见问题
7.3 动态实体常见问题
8. 联系方式
9. 服务条款
AIUI开放平台服务协议
AIUI开放平台隐私政策
小飞在家用户协议
小飞在家隐私政策
小飞在家开源软件使用许可
讯飞账号隐私政策
讯飞账号用户协议
讯飞带屏音箱用户协议
讯飞带屏音箱隐私政策
AIUI SDK隐私政策
AIUI SDK合规使用说明
本文档使用 MrDoc 发布
-
+
首页
1.4 AIUI平台能力概述
<div style="max-width: 100%; margin: 20px auto;"> <!-- 便签卡片容器 --> <div style="background-color: #ffffff; border-radius: 8px; box-shadow: 0 2px 8px rgba(0,0,0,0.1); overflow: hidden; font-family: 'Comic Sans MS', cursive, sans-serif;"> <!-- 便签头部 --> <div style="background-color: #F4F8FA; padding: 1px 10px; border-bottom: 1px solid #dee2e6; display: flex; justify-content: space-between; align-items: center;"> <div style="color: #0E42D2; font-weight: bold;font-size: 1.3rem;">概述</div> <div> </div> </div> <!-- 带横线的内容区域 --> <div style="padding: 25px; line-height: 29px; background-image: linear-gradient(transparent 26px, #dee2e6 27px, #dee2e6 27px, transparent 27px); background-size: 100% 28px; min-height: 100px; color: #333;"> <div>AIUI平台主要提供设备端离线能力、服务端在线能力,并提供多种交互模式,具体可参考:</div> <a href="#设备端能力(离线)" style="color: #6f42c1; font-weight: 500;"> <strong>- 1、设备端能力(离线)>>>点击跳转   </strong></a> <br><a href="#服务端能力(在线)" style="color: #6f42c1; font-weight: 500;"><strong> - 2、服务端能力(在线)>>>点击跳转   </strong></a> <br><a href="#AIUI交互指导" style="color: #6f42c1; font-weight: 500;"><strong> - 3、AIUI交互指导>>>点击跳转   </strong></a> <div></div> </div> <!-- 便签底部 --> </div> </div> </div> <div id="设备端能力(离线)"> </div> ## 1. 设备端能力(离线) ### 1.1. 前端声学 用降噪、回声消除算法来提高唤醒率、识别率。 - **麦克风阵列** 多麦克风算法,提高远距离识别率。常见阵列如下:  - **波束形成** 使拾音具有指向性,抑制波束外声音。2麦波束示例: 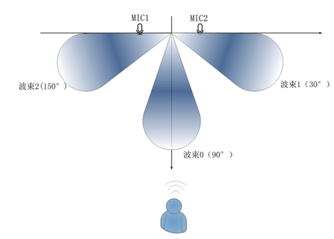 - **回声消除** 回声消除算法抑制麦克风音频中的喇叭声,提高识别率。 - **混响消除** 声波在室内传播时,被墙壁反射形成反射声,并和直达声叠加,构成混响。去混响算法消减声音中的反射声,提升声音的清晰度。 - **噪音抑制** 降噪算法抑制背景噪声,从而提升唤醒率和识别率。 - **声源定位** 唤醒时,根据声音到不同麦克风的时延来确认声音的方位。 ### 1.2. 语音唤醒 用3-6个字的唤醒词,将设备从休眠状态变成识别状态 ### 1.3. 离线语音识别 满足无网络环境下的识别需求。支持标点、和实时出字 ### 1.4. 自定义命令词 支持开发者自定义命令词,最大300词 ### 1.5. 离线语义(语法匹配) 离线语义支持128个槽位、30000个词条,支持用户自由说,可以实现设备的精细控制;配合本地内容资源,还可以满足特定领域语义理解,实现纯离线语音交互,如户外拉杆箱(点歌机)或车载KTV的离线语音点歌。 `注意:离线语义资源消耗:2核1.4G设备,占用CPU15%、内存70M` ### 1.6. 离线合成 支持多种语种的合成,支持音量、语速调节。 <div id="服务端能力(在线)"> </div> ## 2. 服务端能力(在线) ### 2.1. 语音识别 语音识别将声音转换为文本。支持方言。 - **近场识别** 人距离设备 < 1m - **远场识别** 人距离设备 1~5m `注:远场识别引擎,让远距离识别率更高。` - **方言识别** AIUI 支持23 种方言,可动态切换方言引擎。 `注意:语义理解只支持普通话,方言识别会降低语义理解的效果` - **持续录音,连续识别** 交互模式支持**单轮交互(Oneshot)**和 **全双工(Continuous)** **Oneshot**: 一次唤醒,一次交互。如手机 APP 或者语音电视遥控器等单麦克风设备,一般使用单轮交互,需要用户或程序主动触发录音。 **Continuous**:一次唤醒,连续交互。设备需要很好的回声消除效果,且环境安静,`否则自言自语`。 `注意:语音活动检测(Voice Activity Detection,VAD)。用于判断一句话的开始与结束。` - **拒识,过滤无效语音** 全双工模式,通过语义拒识技术,将无效的噪音和无意义语音进行过滤。 `注意:全双工模式仍有小概率的误触发问题。` ### 2.2. 语义理解 语义理解(NLP)指将自然语言转化为结构化数据。 例:将“合肥天气”处理成JSON数据: ```json { "city":"合肥", "time": "2018-01-19" } ``` ### 2.3. 敏感词过滤 敏感词指涉黄、涉暴、涉政、涉恐等词汇。 敏感过滤把敏感词屏蔽,不展示给用户,默认关闭,可[联系AIUI开启](mailto:aiui_support@iflytek.com)。 ### 2.4. 语音合成 语音合成(TTS)指将文字转化为声音。支持方言,外语发音人,也支持定制发音人。 ### 2.5. 信源内容 内容(信源)指语义理解后的有效数据,例如天气信息,音乐的播放链接。AIUI 技能商店中多数技能包含内容。我们诚邀内容提供商与我们合作,包括但不限于音视频资源、流媒体、新闻、自媒体、儿童故事与游戏、股票违章查询等功能类资源。 ### 2.6. 语音翻译 AIUI支持英、日、韩、法、西、俄、阿拉伯等语种的翻译。 翻译属于增值服务,需[联系AIUI开启](mailto:aiui_support@iflytek.com)。 ### 2.7. 交互认知大模型 AIUI支持配置交互大模型服务能力,在传统语义基础上,提高多轮交互、闲聊问答效果。 <div id="AIUI交互指导"> </div> ## 3. AIUI交互指导 ### 3.1. 按键交互 设备有录音按钮,按下录音,松开后停止录音。 ### 3.2. 语音唤醒交互 用户先喊唤醒词,设备被唤醒后才能进行语音交互。 ### 3.3. 全双工交互 指设备喇叭发声的同时录音,无需唤醒词打断,用户可以跟设备对话。` ~~~ 用户:小飞小飞,今天天气 音响:今天晴…… 用户:明天呢 音响:明天多云…… ~~~ ### 3.4. 离线语音交互 离线语音交互是将语音交互需要的服务下发至本地,通过本地解析实现原本只能在线才能支持的语音交互服务。AIUI离线语音交互服务支持开发者定制更新资源,进一步的提升设备化个性语音交互体验。 `离线交互算力占用` 2核1.4G芯片:cpu占用15%;内存占用70M; ### 3.5. 免唤醒交互 [免唤醒语音交互](https://aiui.xfyun.cn/solution/wakeup)实现了直接说话控制设备;没有网络也可以使用 `免唤醒+离线交互算力占用` 2核1.4G芯片:cpu占用35%,内存占用90M; ### 3.6. 多模态交互 多模态交互,融合声纹识别,手势识别、唇形检测、虚拟人形象等AI技术,让人机交互方式更丰富,交互过程更自然。 用户可基于业务场景选择各个能力,并通过自定义技能及技能后处理实现交互流程的设计。
admin
2025年9月16日 17:23
转发文档
收藏文档
上一篇
下一篇
手机扫码
复制链接
手机扫一扫转发分享
复制链接
Markdown文件
分享
链接
类型
密码
更新密码